
Creating and analyzing multilingual parliamentary corpora
Résumé
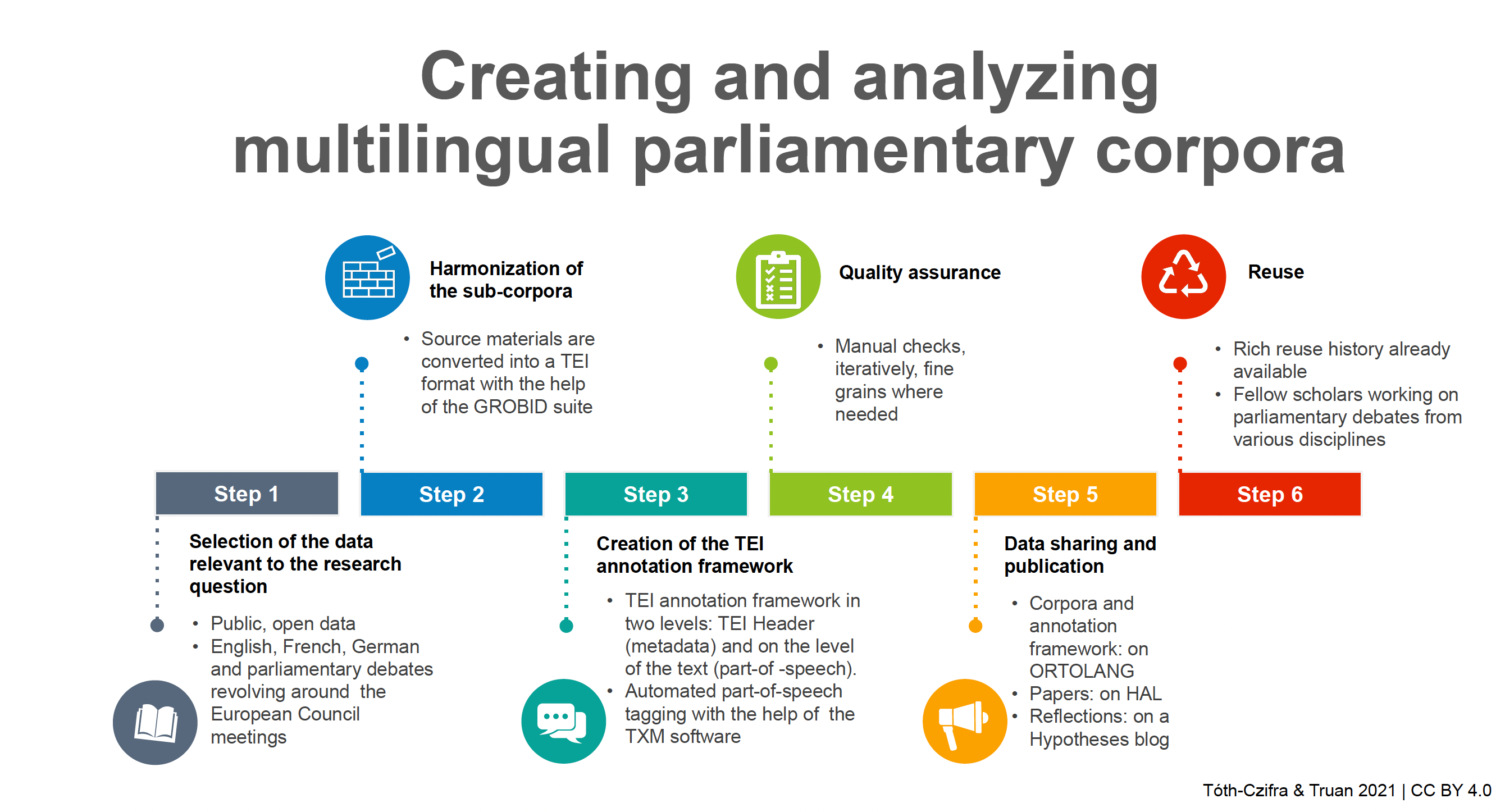
In this resource, you can follow a step-by-step description of a research data workflow involving the annotation of multilingual parliamentary corpora (French, German, British) according to the guidelines of the Text Encoding Initiative (TEI). Read further if you are interested in working with the TEI, analyzing parliamentary corpora, or simply would like to see a validated example of how FAIR and open data is implemented in the context of a PhD dissertation in Corpus Linguistics.
Fichier principal
 Creating and analyzing multilingual parliamentary corpora_RDM.pdf (2.49 Mo)
Télécharger le fichier
Creating and analyzing multilingual parliamentary corpora_Schema.pdf (106.68 Ko)
Télécharger le fichier
Creating and analyzing multilingual parliamentary corpora_Schema.png (1.36 Mo)
Télécharger le fichier
Creating and analyzing multilingual parliamentary corpora_RDM.pdf (2.49 Mo)
Télécharger le fichier
Creating and analyzing multilingual parliamentary corpora_Schema.pdf (106.68 Ko)
Télécharger le fichier
Creating and analyzing multilingual parliamentary corpora_Schema.png (1.36 Mo)
Télécharger le fichier
| Origine | Fichiers produits par l'(les) auteur(s) |
|---|


{kind=link}